注意:本文只是介绍了整个训练过程的大概流程和使用工具,不涉及详细的操作。训练的具体教程和内容可以浏览本文最底部链接里的 Jupyter Notebook 查看。
做了件什么事情?
目标检测是计算机视觉应用的一个方向,随着深度学习技术的发展,基于深度学习的目标检测开始变为主流,在无人驾驶、人工智能、人脸识别等领域大量使用。目标定位能够标出物体所在位置,目标分类能够判断在图像中是否含有该物体,而目标检测则是将两者相结合。
因为有个课题的方向需要运用到目标检测这方面的技术,所以尝试了一下目前主流的目标检测技术。下方是一段b站养鱼up主的一段视频( 视频来源:零基础养鱼第二步——鱼要养得活 @ 我家有个动物园SUN)中的截图,图中的观赏鱼🐟都用框框标示了出来,在这些方框的上方都标有 poisson (法文:鱼)字样,旁边有介于0到1之间的数值代表了置信度。


YOLOv4 算是目前比较强悍的一种目标检测算法,其全称是 You Only Look Once: Unified, Real-Time Object Detection,它在速度和精度都很有优势,Real-Time Object Detection 意味着它可以实时进行目标检测(检测摄像头或者是视频文件等)。
下图中显示了不同目标检测算法准确度和速度之间的比较。可以看到 YOLOv4 在 MS COCO 数据集上获得了较高的 AP 值(average precision 平均精度),即在同FPS值(帧率)下有较高的AP值。
MS COCO 是一种数据集,包含了80种物体分类、33万张图片、150万个目标对象。相比而言,本文使用到的数据集仅只有1种物体(观赏鱼)、122张图片(大多数来自b站萌宠区直播视频截图)、大约1000个不到目标对象(观赏鱼)。本文所使用的数据集(图片和标注数据)和训练结果(.weight文件,约250Mb)可以在本文最底部链接中下载。
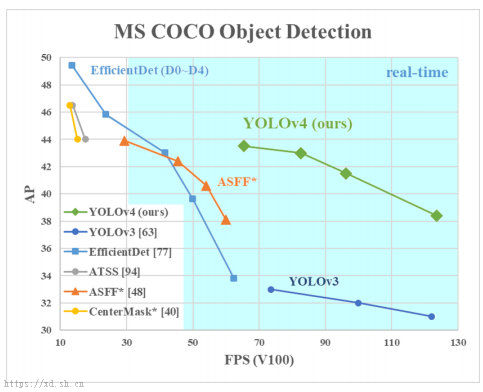
上文图片来源:https://github.com/AlexeyAB/Darknet
本篇文章主要内容如下图所示:首先使用 Labelimg 制作自己的数据集,然后白嫖 Google Colab (以下简称 Colab) 或 百度 Ai Studio (以下简称 Ai Studio)的服务器和显卡。在使用 Darknet 框架下,制作自己的数据集并训练自己的 YOLOv4 模型,得到 .weights 权重文件。
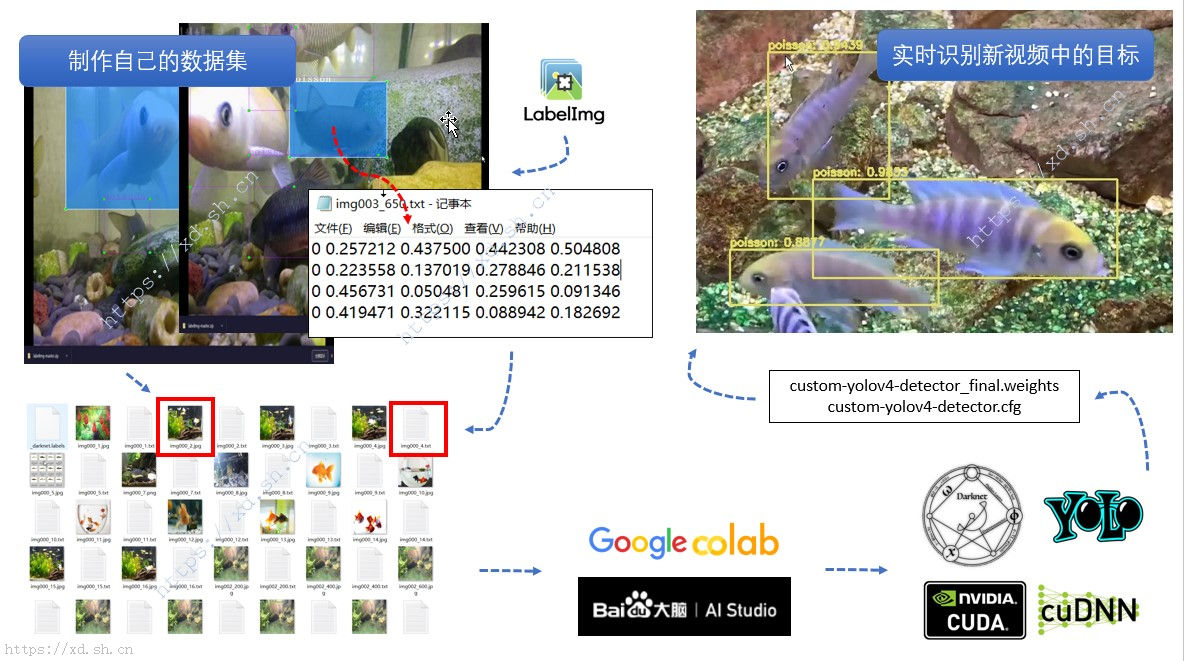
使用了哪些工具?
首先是使用到的软件,软件工具包括了以下这些(注意下列列表中的软件,仅针对使用 Ai Studio 或者是 Colab。若使用自己的电脑进行训练,则需要更复杂的步骤来配置环境。):
在自己的电脑上处理数据
-
Anaconda(用 Python 来处理一些重复的无意义操作,比如文件重命名、视频截帧。)
- Labelimg (用来进行物体目标标注。可以从 github 上直接获取,但是获取之后需要自行安装 Python 环境。)
详见后文:制作自己的数据集。
在 Ai Studio 或者 Colab 上训练
- Darknet YOLOv4 (用来进行训练,服务器上配置。可以从 github 上直接获取,但是获取之后不能直接用,需要自行编译。)
若使用自己本地环境进行配置,则需要安装 Nvidia Cuda 和 CuDNN 以加快训练速度,还要有一块大显存的、高性能显卡。而如果使用 Ai Studio 和 Colab 进行训练则无需担心这些环境配置问题,也无需担心显卡性能问题,两者均配置了拥有 16GB 显存的英伟达特斯拉显卡。
我分别尝试了使用自己本子上的 Windows 和 Ubuntu 以及在线的机器学习环境 Ai Studio 和 Colab 进行编译和训练数据,其中 Windows 和 Ai Studio 在编译 Dartnet 这一关就卡住了(一直编译错误,可能和 Cuda 和 CuDNN 没装对有关)。
而在 Ubuntu 上始终无法使用 CuDNN 进行训练,但是可以用单个 GPU 进行训练。使用我的破笔记本(Nivdia MX150(2018年轻薄本主流配置)),随便试了几张图(注意:只有几张图),结果不是“显卡内存不足”就是训练用时需要10个小时以上。
后来分别使用了 Ai Studio 和 Colab 的分别进行数据训练。两者实际上没有优劣之分,只不过在使用 Ai Studio 的时候,在编译 Darknet 的时候始终遇到错误;而在使用 Colab 训练时间过长之后,会发生丢失文件的情况。Colab 提供的服务器、包括磁盘都是临时的,而不是永久的。所以在服务器上的任何改动,在关闭或者将服务器闲置时,上面所有的资料将会清空。在使用完这些服务器训练之后,要及时地将训练过后的权重文件以及配置文件下载下来。
先试试别人的数据集
在前文提到过数据集 MS COCO,在 Darknet 的 Github 的仓库下面(https://github.com/AlexeyAB/Darknet),作者提供了使用 MS COCO 数据集训练出来的权重文件可以作为测试使用。本文所使用的数据集(观赏鱼的图片和标注数据)和训练结果(.weight文件,约250Mb)可以在本文最底部链接中下载。
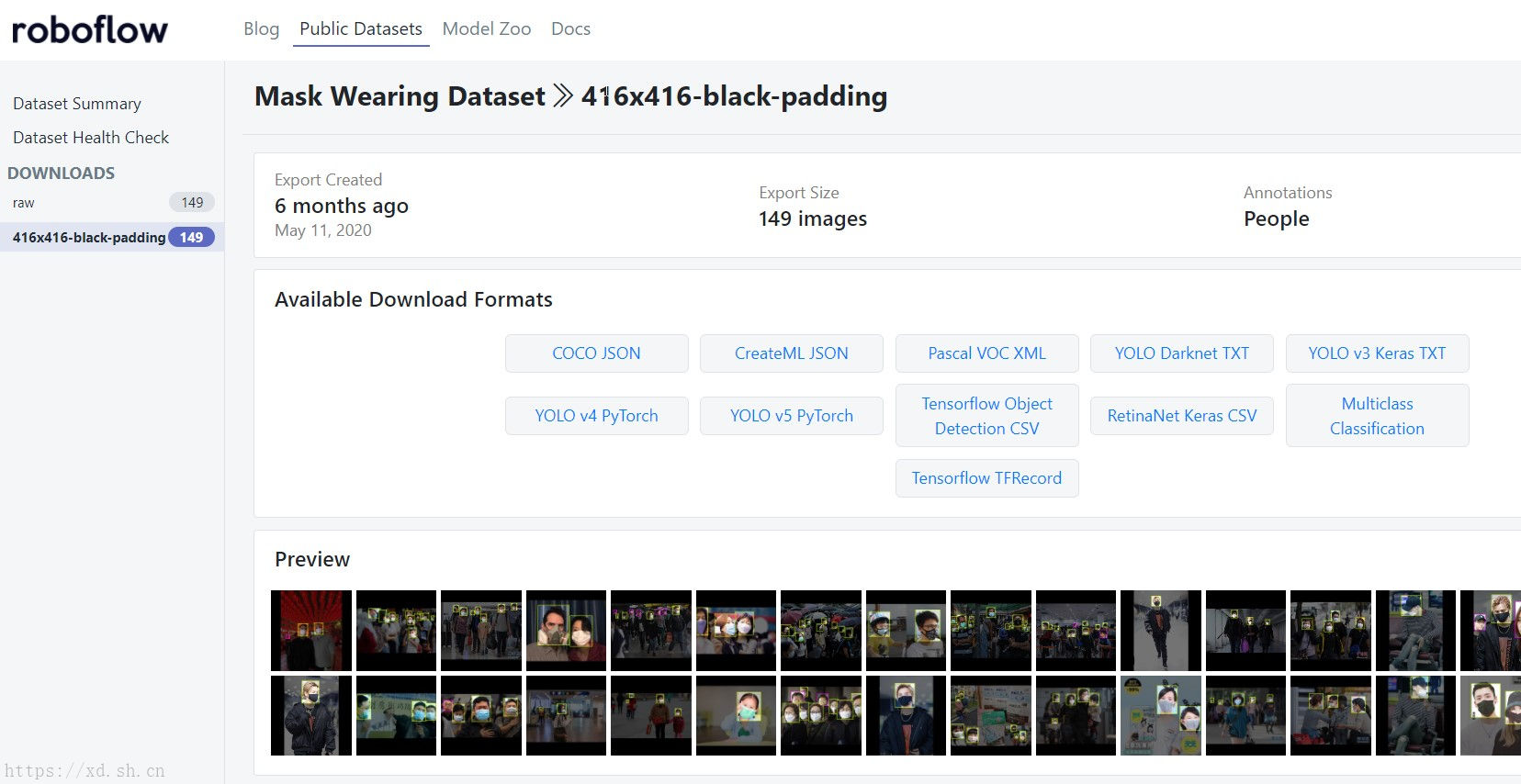
此外,这里还推荐一个数据集的分享、制作网站 Roboflow。虽然这上面的数据集也不是特别多,但是它可以用于小批量的测试,且每种数据集和标注数据都能下载成不同的格式以对应不同的目标检测算法。下方的截图所示为“是否戴口罩”的数据集,数据集内包含了戴口罩和不戴口罩的人,包含了149张原始图片和标注数据。点击 YOLO Darknet TXT 按钮即可下载适用于 YOLO Darknet 的数据集格式,既可以下载为 zip 压缩包,也可以直接使用它提供的链接在训练之前直接调用。
制作自己的数据集
第一步是获得一定数量含有目标的图片。经实测,当检测目标数不是很多的情况下,100到200张图片即可获得不错的检测效果。在上方提到的观赏鱼数据集中,一共仅包含了122张图片。这些观赏鱼图片中有一部分是来自搜索引擎直接搜索,另外一部分来自b站直播的视频截帧:下方链接只是其中的两个,另外的截图原视频来源由于主播未上播、当时也没有记录所以记不清了。
- @小萝卜家的鱼缸 https://live.bilibili.com/14026851
这里可以使用 Python 脚本,截取视频中的截图,代码如下所示:(推荐使用 Anaconda 玩 Python,这样会更加容易管理环境。下方的代码需要在 Anaconda Prompt 中安装 opencv-python:pip install opencv-python)
## 来源:python编程:使用opencv按一定间隔截取视频帧
## https://blog.csdn.net/xinxing__8185/article/details/48440133
import cv2
video_name = '006';
vc = cv2.VideoCapture(video_name + '.mp4') #读入视频文件
c=1
timeF = 200 #视频帧计数间隔频率
while rval: #循环读取视频帧
rval, frame = vc.read()
print(rval,frame)
if(c%timeF == 0): #每隔timeF帧进行存储操作
cv2.imwrite('image_raw/'+'img'+ video_name + '_' + str(c) + '.jpg',frame) #存储为图像
c = c + 1
cv2.waitKey(1)
print('输出1张图片')
vc.release()接下来一步需要用到目标标注软件:Labelimg(https://github.com/tzutalin/labelImg)。这是一个用 python 写成的目标数据标注软件,用户可以用它来标注自己图片中的目标。使用方法也很方便,我使用了最简单的 Windows + Anaconda 的方案:首先傻瓜安装 Anaconda (Python 3 及以上),然后打开 Anaconda Prompt 安装 pyqt5 和 lxml:
conda install pyqt=5
conda install -c anaconda lxml将 Labelimg 克隆至本地或者下载 zip 压缩包到本地,用 Anaconda Prompt 打开 Labelimg 文件夹(路径根据自己的实际情况更改):
cd C:UserssheldDownloadslabelImg-master
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py接着就会打开 Labelimg 的 GUI 界面,因为是图形操作界面,没有太多可说的,操作十分便捷:按键盘上的 w 键即可快速画框框。
要注意的是:
- 如果需要使用 YOLO 作为数据输出格式,那么需要在软件的左侧进行设置。
- 每画完一张图需要保存,当然也可以使用它的“自动保存”模式。
- 如果所标注的对象只有一种,那么可以使用“单目标标注”模式,更加快捷。
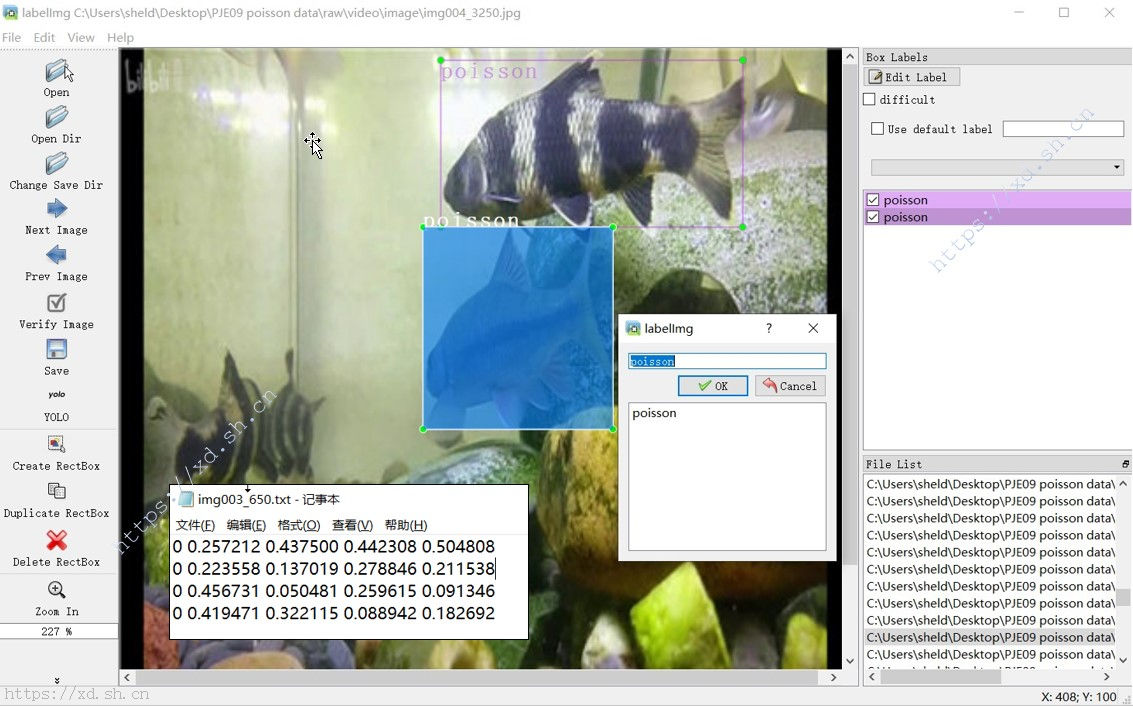
- 每张图片将单独保存为一份 txt 文件,内容为所画方框的坐标,如下图左下角。(0 对应了检测目标列表的序号,在这里代表了 poisson。若有多种物体,则该序号则会不同。)
使用 Ai Studio 或 Colab 进行训练
在使用 Colab 的时候,整个操作均在一个 Jupyter Notebook(学 Python 必备神器)中执行,所以找到了一个实例 Jupyter Notebook(darknet 仓库下方有个官方的 Notebook),这个 Jupyter Notebook(.ipynb 文件)亦可在本文最下方的链接中下载。(注意: Colab 会因为一些众所周知的原因无法在国内登录。)
在使用 Ai Studio 训练时一直遇到:当 Makefile 文件中 GPU = 1 时, Darknet 编译遇到错误,所以暂时放弃了使用 Ai Studio。然而,若不使用 GPU 进行训练,则环境可以仅使用 CPU 训练,但速度会严重降低。
Jupiter Notebook 文件在 Ai Studio 中亦可使用,但 Ai Studio 没有对飞浆以外的算法进行适配,GPU环境可能不兼容。不过只要在使用 Ai Studio 时 Darknet 可编译成功,那么就可以按照官方步骤顺利进行后续的训练。
-
Ai Studio :https://aistudio.baidu.com/
- Colab:https://Colab.research.google.com/
这里不细说如何修改配置文件等细小的操作内容,因为整个操作过程均可以使用 Jupyter Notebook 完成,所有细节都能在这个.ipynb 文件中找到。这里仅说一下大概的流程:
-
查看 Cuda 版本号和显卡型号,下载、安装并配置对应的 CuDNN。
-
看看显卡的型号:Colab 是一块 16Gb 显存的英伟达 Tesla T4,Ai Studio 是一块 16Gb 显存的英伟达 Tesla V100。(百度用的显卡性能更强。)
-
根据显卡型号和 Cuda 版本安装 CuDNN,但是这步基本上略过,因为环境基本上都预先布置好了。
-
安装 Darknet
- 从 https://github.com/roboflow-ai/Darknet.git 克隆 Darknet 并解压。
- 修改 Darknet 文件夹中的 Makefile 文件,把 GPU 和 CuDNN 都用起来!
- 使用 make 命令编译 Darknet。
- 下载 YOLOv4 ConvNet weights 文件并放入 Darknet 文件夹: yolov4.conv.137` 。
-
上传自己的数据集,并且解压在 Darknet 文件夹中。
-
新建并配置 obj.data 、train.txt、valid.txt 等文件。( Jupyter Notebook 中一段 Python 代码搞定 )
-
新建并配置 YOLOv4 的自定义文件
custom-yolov4-detector.cfg。( Jupyter Notebook 中一段 Python 代码搞定 ) -
使用
./Darknet detector train data/obj.data cfg/custom-yolov4-detector.cfg yolov4.conv.137 -dont_show -map就能训练啦!训练用时约10小时,每隔一段时间就会在 backup 文件夹下生成一个权重文件。 - 训练完成之后,最后一个权重文件为
custom-yolov4-detector_final.weights。

验证自己的训练结果
- 最简单的验证方法可以直接在训练完的 Darknet 文件夹内完成( Jupiter Notebook 中 Python 代码搞定)。
- 借用一个使用 PySimpleGUI 写的 Python 程序,叫做 [PySimpleGUI-YOLO]() https://github.com/PySimpleGUI/PySimpleGUI-YOLO,克隆或者下载下来之后解压缩。使用 Anaconda 安装 opencv-python 和 pysimplegui 包之后,即可运行。运行的效果就如本文开头所示。
结语
目标检测的旅程远还没有结束,本文只是介绍了整个训练过程的大概流程和使用工具,不涉及详细的操作和原理。训练的具体教程和内容可以浏览本文底部链接中的 Jupyter Notebook 查看。
附件
附件中包含了:
- 观赏鱼 yolov4 训练后权重文件
- custom-yolov4-detector.cfg
- custom-yolov4-detector_best.weights
- custom-yolov4-detector_final.weights
- python 数据处理小脚本
- 观赏鱼 yolov4 数据集.zip (1种物体(观赏鱼)、122张图片(大多数来自b站萌宠区直播视频截图)、大约1000个不到目标对象(观赏鱼)。)
- yolov4.conv.137
- YOLOv4-Darknet-Poisson-Jupter-NoteBook.ipynb
链接地址: